Data from a Wainhouse Research report shows that 27% of enterprises that are over 500 employees are adding at least 25 hours of on-demand video content to their archives each month. This explosion of content is proving key for applications like training and educating a workforce, or used as collateral to engage prospects. However, with these growing archives also comes with it a challenge of discovery, of being able to quickly locate relevant content when needed.
One way to address this challenge, though, is by improving overall content discoverability. This can be achieved through implementing a sophisticated enterprise video search and improving metadata for your video assets, ideally though methods that don’t also increase the time commitment to managing the video archive. This article talks about ways to improve asset discovery, why it should be something to strive for, and discusses recent updates using IBM Watson that are aimed at addressing these needs.
- Enterprise video search
- Video search filters
- Video asset transcription for discoverability
- How to transcribe videos with IBM Watson
- API search calls
Enterprise video search
As enterprise video libraries increase in size, employees and other stake holders need a way to cut through the “clutter” to find that one piece of content that is most relevant for their current need. A way to address that is through adding a search function to the video library. This ability to search is already widely desired by enterprises today. In fact, among organizations with archives containing 100+ hours of video content, 74% see the ability to “search content to find relevant videos” as very important or essential in influencing their streaming technology purchase decision.
So any internal video library of a decent size should incorporate a way to search that content.
With IBM, enterprise video streaming accounts have the ability to create a video portal. These portals are made up of live and on-demand video content. The portals are also secured, restricting access to intended parties usually through integrating with a corporate directory. Read more on these security features here. This portal content is then segmented based on channels, which are organization defined. For example, these channels can be based on departments, like a finance or HR channel, or by function, like sales training or executive town halls. For more details on content portals, please see our video portal guide for customizing them.
Advantageously, these video portals already contain a built-in search feature. This allows employees and other authorized users to search through the content to find videos most relevant for them. It also includes the ability to sort these results. The sorting criteria includes being able to sort by:
- Newest
- Oldest
- Most viewed
- Shortest
- Longest
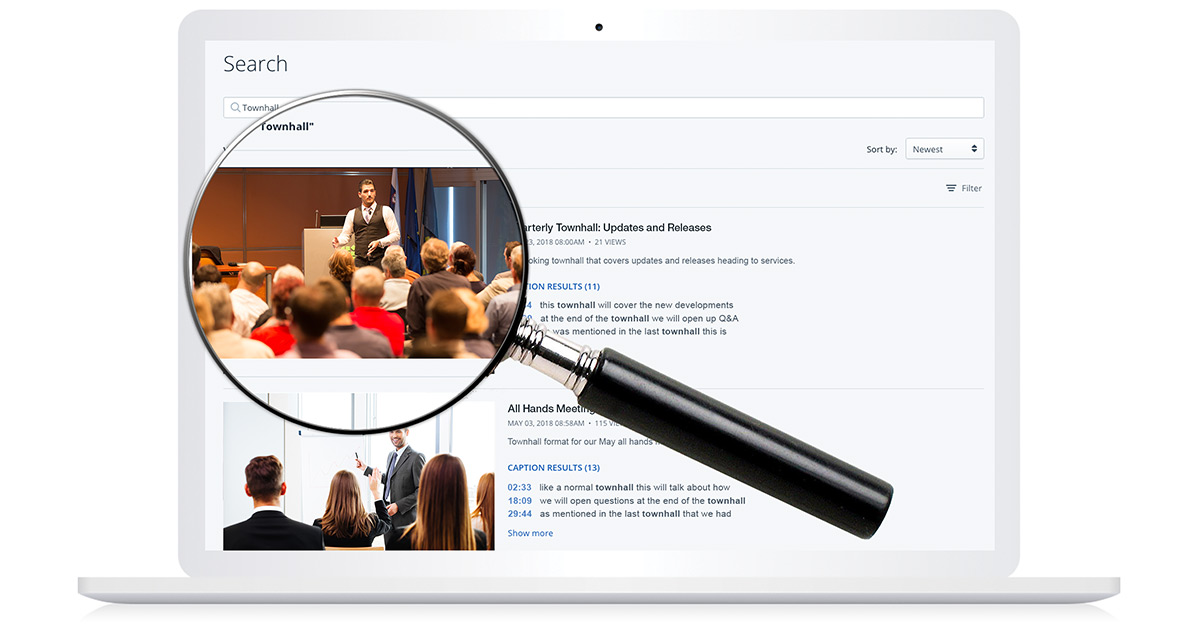
After a search inside the portal, relevant assets related to the query will be displayed. This includes showing where in the transcription the term came up and at what moment, helping viewers determine which of the assets they are most interested in before watching.
Video search filters
While sorting is one piece of the puzzle, there should be a way to further refine results to increase relevancy. As a result, after providing a mechanism to search a video library, the next step is providing tools to help narrow that search. This can be achieved through search filters.
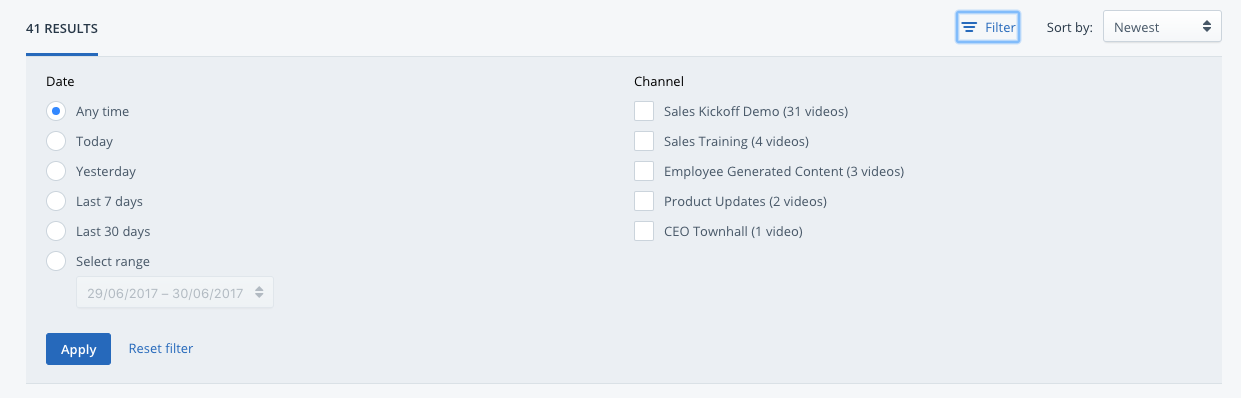
Recently added to IBM Enterprise Video Streaming accounts, search filters provide a quick way to narrow down content searches. These filters can sort by date and/or by channel.
The ability to sort by date can allow employees or other stake holders the ability to narrow down results to the most recent content. Default ranges include content that was uploaded today, in the past week or in the past month. A custom range can also be defined, searching over the span of a year or narrowing the search window to a few days over a specific period. This can aid in locating recent, possibly more timely assets. It can also help in discovering a specific piece of content during an event. For example, if a content was being streamed during a company retreat in October of 2015, the search window could be narrowed to look for content uploaded or archived during that period.
The search can also be filtered by channels on the account as well. When content is filtered by a channel, this process can directly work with an internal content organization structure. Since enterprises are able to create channels in a way that makes sense for their organization, these channels can be a mixture of by use case or by department. For example, there might be a channel associated with the engineering department, while another might be associated just with training around sales procedures. By being able to filter, content can be narrowed to relevant categories. Furthermore, the filters aren’t exclusive. This means someone can select multiple channels to search at once, for example, highlighting a series of training channels.
The next piece of the puzzle is improving what content can show up in search results, to improve discovery of relevant content. This is done through finding ways to enhance the metadata around videos.
Video asset transcription for discoverability
Metadata for video assets are an important component of improving their discoverability. However, even if an organization thinks they know what elements of the video might be important, they still might gloss over an angle that some will use to search their video libraries. A way to address this is to transcribe the video and make the entire dialogue something that can be searched against. That way, for example, if an executive mentions a certain product’s financial performance during a meeting but it’s not tagged in the natural metadata, it still might be incorporated into results for those inside your organization looking for collateral around that term.
However, manually transcribing a video is time consuming or costly, or both. Furthermore, the transcription needs to be accurate. The last thing an organization wants is for a false positive to be triggered because a transcription was done incorrectly. Consequently, for many organizations these become barriers for transcribing their video library.
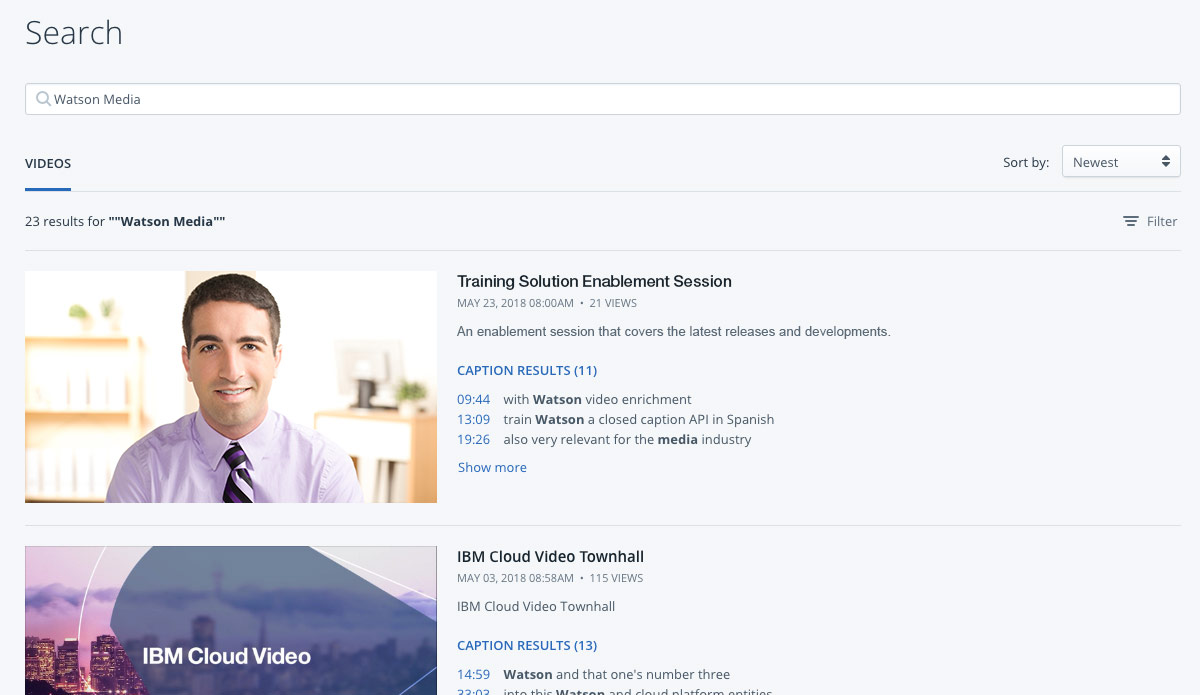
Luckily, through a recent update, IBM has introduced IBM Watson capabilities to resolve transcript creation issues. Utilizing IBM Watson Speech to Text, organizations can transcribe their entire library of video assets. In fact, it roughly takes the length of the video session to transcribe it (so a ten minute video takes around that time to transcribe). This transcription creates captions for these assets as well, which can be manually edited for accuracy. Furthermore, one can search inside the video for specific moments also using these captions.
How to transcribe videos with IBM Watson
 Video transcription is currently available to IBM Enterprise Video Streaming users. The technology is integrated into the platform, making it easy for content owners to transcribe their video assets.
Video transcription is currently available to IBM Enterprise Video Streaming users. The technology is integrated into the platform, making it easy for content owners to transcribe their video assets.
When IBM Watson begins to work on a video, it will generate a transcript for that video asset. This automates an otherwise very timely practice. To maintain accuracy, a confidence level is attached to each video asset as well. Currently, and subject to change, any confidence level below 70% means the transcript will not be used. This level means a large amount of content will be transcribed without leading to videos with grossly inaccurate transcriptions being included in search results.
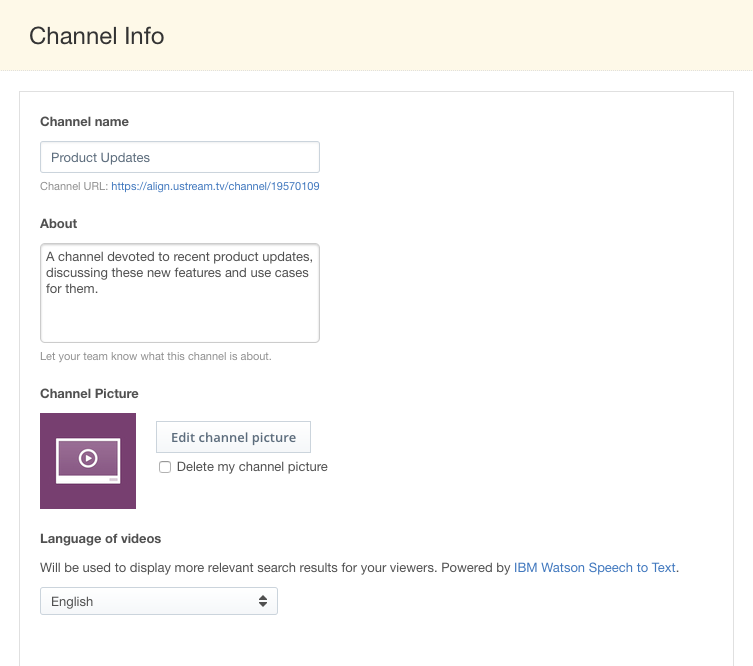
Transcription is done through setting a language inside a channel. This can be navigated to by going to the channel and then clicking “Info”. One of the options on this page is called “Language of Videos”.
Selecting a language, as long as it’s supported, will then proceed to generate transcripts for all video content associated with that channel. Currently supported languages include English, Arabic, Chinese, French, Japanese, Portuguese and Spanish. New languages will be added as time goes on.
Note that you can change the language later on and have it generate new transcripts using that language as a frame of reference. However, this is only advised if the original selection was saved in error, or the vast majority of the content has indeed changed languages over time.
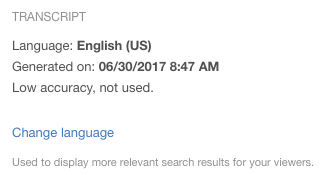 That said, there can be scenarios were a video on an account is done in a different language. For example, video assets might be compliance related and an organization might have versions that are in English, Spanish and French. To address this scenario, content owners can also go in and manually set a language on a per video basis for content inside a channel. In this scenario, it would be very common to go to the video and get a “Low accuracy, not used” message, since it was attempting to transcribe the video in a different language. However, by clicking on that channel, going to “Videos” and then editing the video in question, an administrator or channel manager can change the language selection.
That said, there can be scenarios were a video on an account is done in a different language. For example, video assets might be compliance related and an organization might have versions that are in English, Spanish and French. To address this scenario, content owners can also go in and manually set a language on a per video basis for content inside a channel. In this scenario, it would be very common to go to the video and get a “Low accuracy, not used” message, since it was attempting to transcribe the video in a different language. However, by clicking on that channel, going to “Videos” and then editing the video in question, an administrator or channel manager can change the language selection.
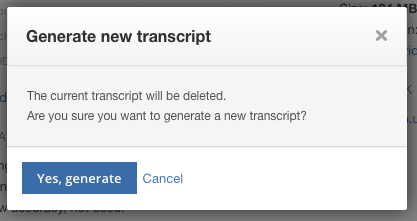 After the language is changed on a particular video, a prompt will appear to confirm the generation of the new transcript.
After the language is changed on a particular video, a prompt will appear to confirm the generation of the new transcript.
Once generated, assuming the confidence level is high enough, the transcript will then be associated with that video and appear in searches made on the video portal looking for video assets.
API search calls
The API (application program interface) aspect of IBM Watson Media has also been expanded to take advantage of these additional search parameters. This includes being able to search against not just transcripts but the captions created through the Convert Video Speech to Text with Watson feature. When using the API search query called “caption_matches” it will not only search against this for a relevant part, but also return back an end time in the response as well.
Below is a sample of the code response using this API call:
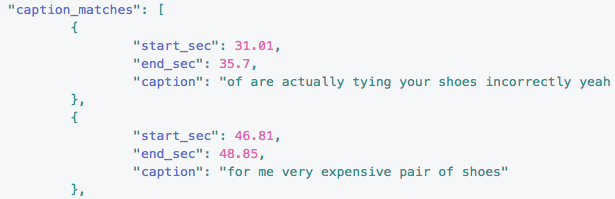
Learn more about the Channel APIs here.
Summary
As the value of internal facing video continues to be publicized, more organizations are not just embracing it but increasing the amount of video content they store. In fact, from a joint IBM and Wainhouse Research report, 19% of organizations are adding at least 25 hours of video to their corporate libraries each month, up from 12% in 2013.
This boom in internal video brings with it the need to be able to effectively navigate the library to find the most relevant content. In fact, according to the same Wainhouse study, 79% of executives with video content archives agree that “a frustration of using on-demand video is not being able to quickly find [information]”. The solution for this is adopting enterprise video search functionality, with ways to refine and filter those results. However, a good internal video strategy also includes a rich metadata strategy, which effectively adds relevant context to a video to improve the likelihood it will come up in searches. Making the transcript for that video searchable is one way to enhance this, although building this out manually can be both costly and time consuming. Adding in artificial intelligence transcription through IBM Watson’s speech to text capabilities, though, not only removes the cost hurdle but also the time restraint element as well. Together, these can greatly bolster the effectiveness of an organization’s video library, making relevant content easier to discover.
Want to start taking these features for a test drive?
Sign up for IBM Enterprise Video Streaming.
