
Looking for live broadcast closed captioning solutions?
IBM Watson Captioning offers a service for broadcast television to caption their live content. This uses a combination of artificial intelligence in the cloud and hardware on location. For the on-premise component, the Watson Live Captioning RS-160 is hardware created specifically for this use case by the Weather Company to complement the Captioning service. For accuracy, the AI can be trained in advance, expanding both vocabulary and relevant, hyper-localized context through providing corpus.
This delivers a solution that can not only be highly accurate, but one that is both scalable and built for high availability.
To learn more about automatic closed captioning, register for our Auto Closed Captions and AI Training webinar.
- Workflow
- Training the AI for live captions
- Vocabulary training
- Corpus and contextual training
- How scripts are used in automatic captioning
- Highly available with redundancies
Workflow
The high level workflow for live captioning for broadcasting is this:
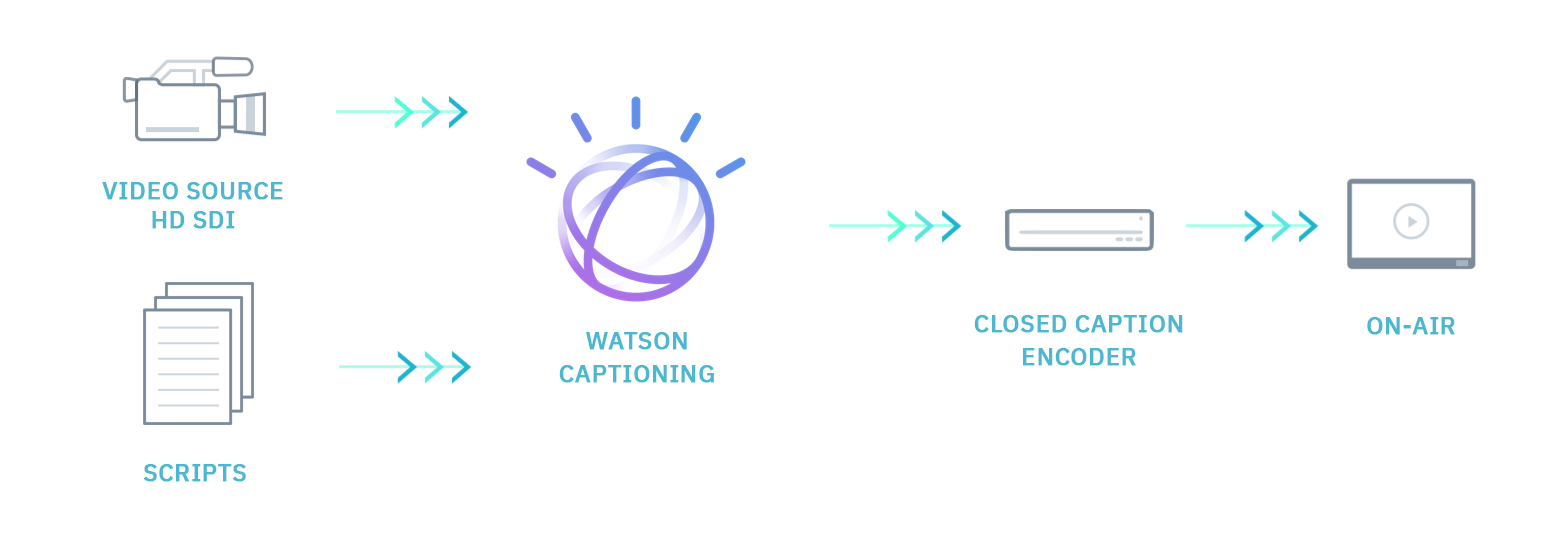
On the far left is the video source, brought in through HD-SDI. There is also the story scripts, brought in through a service like iNEWS or MediaCentral. Both of these sources are then fed into Watson Captioning, live in the case of the video content and ideally at least 20 minutes in advance in the case of the story scripts.
From this, Watson Captioning begins to generate a transcript using speech to text. This is then fed over IP or serial to a closed caption encoder, such as the EEG HD492. These are then delivered as 608 captions live on the broadcast, allowing end viewers to watch closed captioned content live.
This process is scalable, allowing rigorous training to be used again and again to generate accurate captions for live content.
Training the AI for live captions
When doing on-demand captions, content owners have the luxury of going in to edit results after the fact. While this can produce flawless captions, it’s a luxury not available for live content. As a result, a lot of importance is placed on having the artificial intelligence generate highly accurate captions from the start. This is achieved through extensive training of the AI.
This is a category where Watson Captioning shines. Through leaning on the robust learning capabilities of IBM’s Watson, content owners can effectively train the artificial intelligence so it will be equipped for the task of transcribing a specific broadcast.
Vocabulary training
Now there are a variety of different ways that the AI can be trained to deliver more accurate captions. The first is on vocabulary training. This is the process of literally teaching it new words. For example, let’s say a report is going to talk about a new service called MaserHub. If the AI hasn’t been trained on what MaserHub is, though, it’s liable to try and transcribe it as “laser hub”, without realizing it’s a noun, a conjoined word and has the spelling of “maser” depending on how it was pronounced. By teaching it this word, though, it will correctly identify it when it comes up in conversation.
In terms of training the AI, this can be done by uploading a UTF-8 encoded txt or csv file. On these files, each line should contain one word to be taught, with a desired ‘sounds like’ variants afterwards. So a sample for MaserHub might look like this:
“MaserHub, maser hub, laser hub”
Alternatively, the vocabulary can be expanded from a web based dashboard as well. This can be seen below:
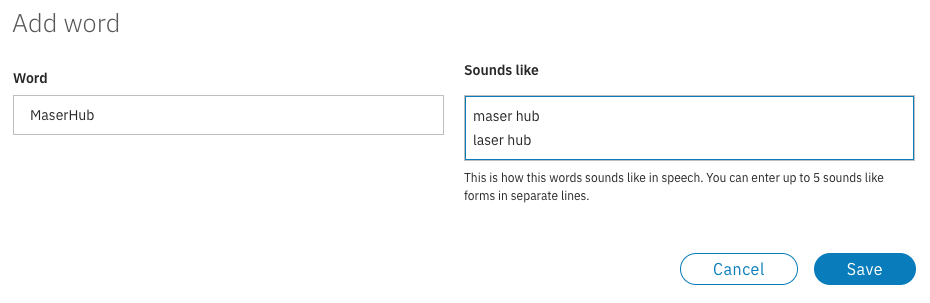
For more details on vocabulary training, in particular the dashboard offering, consult this AI Vocabulary Training article.
Corpus and contextual training
A corpus, a collection of written texts, can also be submitted to train the artificial intelligence. This works by uploading example assets for Watson to learn from and as a result make better, more informed decisions when selecting how to caption something. For example, if it skims through the corpus and notices that when a word that sounds like “hide” is combined with the word “street” it’s generally referring to “Hyde Street”, an actual street that’s a noun as well.
The idea is to train Watson on these use cases, and also bias results toward your application as well. This is particularly true to local landmarks, which might have unique spellings but aren’t globally relevant and teaching these might not improve the accuracy of other broadcasts. On that note, it should be noted that each instance of Watson Captioning has specific training and context associated with it. So for example, if you teach it about “Hyde Street”, another broadcaster will not automatically benefit or have this available to them as well. This helps preserve individual work, and also allows content owners to bias the results in a preferred manner as well.
Now uploading corpus can be done in two ways. The first is to provide completed caption files, in the SRT or VTT format. The second is to provide a custom document that contains a single sentence per line. Both should be error free before submission, as Watson will use this to learn from.
How scripts are used in automatic captioning
It’s hard to think of a better reference or training source for captioning something than access to the script. This will ideally give the AI a lot of contextual information and a clean cut view of relevant vocabulary as well.
Now it should be noted that the AI does not use the script verbatim to caption assets. So for example if a reporter goes off script, adding a comment of their own to the story, this will not throw off the captioning process. The AI simply uses the script as a frame of reference, especially in relation to context. For example, if a reporter says “the demonstration happened on Scenic Drive” it will have the script to reference and realize that Scenic Drive is a noun and should be capitalized and is not referencing someone going on a scenic drive of a nice area.
This is a component of the rich training capabilities present to help deliver accurate captions.
Highly available with redundancies
When something is live it has to work. There isn’t time to fix something after the fact. As a result, IBM has doubled down on reliability as a cornerstone of the Watson Captioning solution for live, broadcasted content.
There are a couple of different ways this is achieved. One is highly available [matrixed] cloud instances, with access to the captioning technology. In addition, redundancies are also created on the client side and with redundancies in the data centers, allowing for an instance to fail yet not hamper the overall caption process for on-air content.
Summary
Watson Captioning can offer a scalable, cost effective solution for broadcasters. One that greatly reduces required manpower, while avoiding past concerns like “peak usage” when numerous news organizations all had breaking news stories around a big event that saw surge pricing take effect.
The solution continues to grow and improve as it’s used as well, taking past training and using it to effectively generate future captions.
To learn more on using AI for caption generation, also download this Captioning Goes Cognitive: A New Approach to an Old Challenge white paper.