
Closed captions have grown to be an important part of the video experience. While they assist deaf and hard of hearing people in enjoying video content, a study in the UK discovered that 80% of closed caption use was from those with no hearing issues. Not only that, but Facebook found out that adding captions to a video increased view times on their network by 12%. These reasons, along with regulations such as the Americans with Disabilities Act and rules from the FCC, have realized the need to caption video assets. However, caption generation can be time consuming, taking 5-10 times the length of the video asset, or costly if you are paying someone else to create them.
A solution is automatic speech recognition from machine learning. This the ability to identify words and phrases in spoken language and convert them to text. The process offers content owners a way to quickly and cost effectively provide captions for their videos. To address this, IBM introduced the ability to convert video speech to text through IBM Watson. This was added to IBM’s video streaming solutions in late 2017 for VODs (video on-demand). It has recently been expanded to recognize additional languages.
Integrated live captioning for enterprises is also available, although differs in several ways from the VOD feature talked about here.
- How it works for VODs
- Supported languages
- Caption accuracy
- Steps to convert video speech to text
- Exporting and editing captions
- Additional professional services available for captioning
How it works for VODs
IBM Watson uses machine intelligence to transcribe speech accurately through combining information about grammar and language structure with knowledge about the composition of the audio signal. As the transcription process is underway, Watson will continue to learn as more of the speech is heard, providing additional context. Through this process, it will apply this added knowledge retroactively, so if clarity to an earlier statement is introduced toward the end of the speech Watson will go back and update the earlier part to maintain accuracy.
To convert video speech to text, content owners simply need to upload their video content to IBM’s video streaming or enterprise video streaming offerings. If the video is selected as being in a supported language, Watson will automatically start to caption the content through using speech to text. This process takes roughly the length of the video to transcribe, producing quick, useable captions.
Supported languages
At launch, this feature supported 7 different languages, with English variants for either the United Kingdom or the United States. This was expanded to support 11 different languages in 2020. Right now the system can recognize the following languages:
- Arabic
- Chinese
- Dutch
- English (UK) or English (US)
- French
- German
- Italian
- Japanese
- Korean
- Portuguese (Brazil)
- Spanish
Being a supported language means that the technology can be set to recognize audio in that language and transcribe it. So English audio would be transcribed to English text or captions, while Italian audio would be transcribed into Italian text.
More languages will be supported as time goes on as we are constantly working on expanding the list of supported languages.
Caption accuracy
Two elements go into the accuracy when converting speech to text.
The first is that any automated speech to text service can only transcribe words that it knows. Watson will determine the most likely results for spoken words or phrases, but might misinterpret names, brands and technical terms. The service continues to advance and learn, though, and as mentioned is setup to review the full speech and make corrections based on context. For example, Watson might transcribe someone as saying “they have defective jeans”, but later context is added that they are talking about genetics and the statement could be amended as “they have defective genes”. In addition, training can be performed on the specific content you plan to feed the speech to text engine, which can dramatically improve accuracy on these specific words. Contact IBM sales to learn more about this optional service.
Second is the quality of the video’s audio, which has a big impact on accuracy. The best results are observed when there is one speaker in your video talking at a normal pace with good audio quality present. Factors that can work against speech to text accuracy include a lot of background noise, including loud soundtracks or soundtracks with vocals, or instances where multiple people are talking simultaneously. Speakers with accents that cause words to be slurred or pronounced differently might also be misinterpreted unless the whole speech provides proper context.
Steps to convert video speech to text
To start automatically generating captions on your videos, you will first need to designate a language for IBM Watson to use. This can be done in two ways:
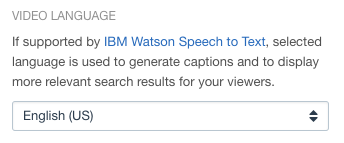 On a channel basis for all associated videos, by going to Info for the channel and setting a language
On a channel basis for all associated videos, by going to Info for the channel and setting a language- On a per video basis, by editing the video and going to Overview and setting the language
Once a language is selected… that’s it. Watson will automatically start to review the available video content and create caption files through speech to text. This process takes roughly the length of the video to create the captions. So a ten minute video would take roughly ten minutes to caption. Once a video has finished the caption process an email will be sent to confirm it’s been captioned.
By default, captions will publish with the content. In other words, when the caption process is done they will be immediately accessible to end viewers. If you prefer to review the captions first, it’s recommended to leave the video unpublished until Watson is finished. After this, you can preview the video without publishing it to check for accuracy. Once satisfied, the video and captions can be published together for viewers to watch.
Exporting and editing captions
IBM Watson Media provides a closed caption editor inside the web based platform. It is recommended to use this to edit captions for a variety of reasons, including ease of use in checking scene to captions for accuracy easily. It also makes it easier to have multiple people editing captions as well.
That said, captions can be edited offline if desired. This is made possible because the captions are generated in a WebVTT file format. This means each caption is associated with a timestamp that designates both when the caption should appear and also when it should disappear. An example caption entry in a WebVTT file would look like this:
0000:03:54.000 --> 0000:04:08.000
The fires were contained through the extraordinary efforts of the Derry firefighters.
In this case, the WebVTT is indicating that a caption will appear at 3:54 minutes into the video, and disappear at the 4:08 minute mark. However, let’s say that we wanted to edit these captions. Maybe, for example, we want to note that Derry is located in Maine by changing it to “Derry (Maine) firefighters”. To do this we would need to export the captions and then edit them.
To export captions, a content owner can select a video and navigate to the Closed Captions tab. This will show a list of available captions, which can be a combination of those generated through Watson and also WebVTT files that were uploaded as well.
Mousing over a caption entry will provide three options: Download, Settings and Unpublish.
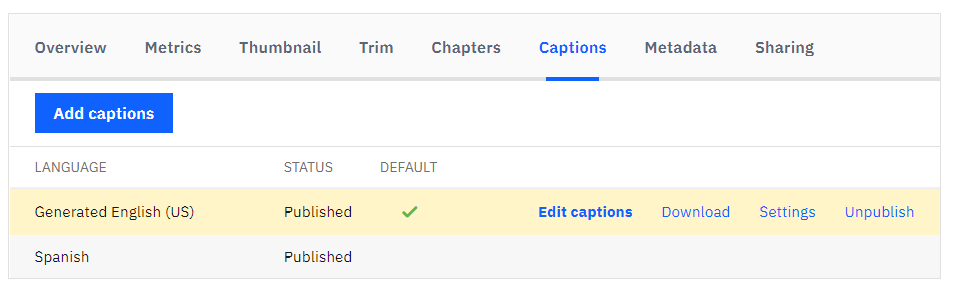
When clicking download, a prompt to save a local copy will appear. This copy can be used for a variety of purposes, from creating a DVD version to just saving a local transcript for records. If you intend to edit it, though, there are a variety of options at your disposal.
First off, WebVTT files can be edited in a simple text editor. So Notepad for Windows or TextEdit for Macs would be able to edit the raw file. In the example above, you could search (Ctrl + F on Windows, Command + F on Macs) to find the passage about the firefighters and quickly edit it. If, however, you prefer something that is a little more graphic oriented to edit the caption file, there are programs specifically designed for this. While many are Windows based, like Subtitle Edit or Subtitle Workshop, these programs will allow you to watch the video file while editing. This might aid people in finding the specific moments they want to edit more easily.
After the captions have been sufficiently edited, you can go back to the Closed Captions tab for that video to add them. This is done through clicking the Add Captions button. This requires that a language for the caption be selected.
Additional professional services available for captioning
IBM offers a comprehensive suite of professional services for importing, maintaining and performing quality control on video libraries and live events. For video captioning, IBM can provide services ranging from making available professional transcription services and translators, to file format conversions for libraries with non-HTML5 compatible captions. In addition, IBM can provide training services for Watson to significantly improve the accuracy of the automatic captions on proper nouns, technical terms, names and industry or company-specific jargon. Contact IBM sales to learn more.

Summary
Converting video speech to text with IBM Watson provides content owners a fast way to make their libraries of video content more accessible. It also ties into general shifting viewer preferences that is seeing more people opt to have captions on videos they watch. As the technology behind the service continues to adapt and grow, expect this feature to improve with time as well, being able to interpret more words, more accents and more languages.